Golang 的版本管理原则
前言
本文翻译+删选+理解自 The Principles of Versioning in Go
为什么需要版本?
让我们先看下传统基于GOPATH的go get是如何导致版本管理失败的。
假设有一个全新安装的 Go 环境,我们需要写一个程序导入D,因此运行go get D。记住现在是基于GOPATH的go get,不是 go mod。
$ go get D

该命令会寻找并下载最新版本的D 1.0,并假设现在能成功构建。
几个月后我们需要一个新的库C,我们接着运行go get C,该库的版本为 1.8。
$ go get C

C导入D,但是go get发现当前环境内已经下载过D库了,所以 Go 会重复使用该库。不幸的是,本地的D版本是 1.0,而C对D有版本依赖,必须是 1.4 以上(有可能 1.4 有一些 bugfix 或者新 feature)。
显而易见这里C会构建失败。我们再次运行go get -u C。
$ go get -u C

不幸的是,(假设)一小时前D的作者发布了D 1.6,该版本又引入了一个缺陷。因为go get -u一直使用最新的依赖,所以使用 1.6 的C又构建失败了。
由这个例子可以看出,基于GOPATH的go get缺乏版本管理,会导致两种问题,要么版本过低,要么版本过高。我们需要一种机制,C和D的作者能够一起开发和测试。
自从goinstall/go get推出之后,Go 程序员就对版本管理有着强烈的诉求,过去几年间,很多第三方的工具被开发出来。然而,这些工具对版本控制的细节有着不同的实现和理解,这会导致不同的库若使用不同的工具,库之间仍然无法协同工作。
软件工程中的版本
过去两年间(2019),官方试图在go命令中引入Go moduless的概念来支持版本管理。Go moduless带来新的库导入语法——即语义化导入版本(Semantic import versioning),而在选择版本时,使用了新的算法——即最小版本选择算法。
你可能会问:为什么不使用其他语言的现成经验?Java 有Maven,Node 有NPM,Ruby 有Bundler,Rust 有Cargo,他们解决版本依赖的思路不好么?
你可能还会问:Go 团队在 2018 早些时候引入了一个试验性的工具Dep,该工具实现上与Bundler和Cargo一致,现在为啥又变卦了?
答案是我们从使用Bundler/Cargo/Dep的经验中发现,它们所谓处理依赖的方法,只会使项目越来越复杂,go modules决定另辟蹊径。
三原则
回到一个很基础的问题:什么是软件工程?软件工程和编程有什么区别?原作者 Russ Cox 使用了这个定义:
Software engineering is what happens to programming when you add time and other programmers.
为了简化软件工程,Dep和Go moduless在原则上有三个显著的改变,它们是兼容性、可重复性和可合作性。本文余下部分会详细阐述这三个指导思想。
原则 #1:兼容性
第一原则是兼容性,或者称之为稳定性,程序中名字的意义不能随着时间改变。一年前一个名字的含义和今年、后年应该完全一致。
例如,程序员经常会对标准库string.Split的细节困扰。我们期望在"hello world"调用后产生两个字符串"hello"和"world。但是如果函数输入有前、后或着重复的空格,输出结果也会包含空字符串:
Example: strings.Split(x, " ")
"hello world" => {"hello", "world"}
"hello world" => {"hello", "", "world"}
" hello world" => {"", "hello", "world"}
"hello world " => {"hello", "world", ""}
假设我们决定改变这一行为,去除所有空字符串,可以么?
不
因为我们已经在旧版string.Split的文档和实现上达成一致。有无数的程序依赖于这一行为,改变它会破话兼容性原则。
对于新的行为,正确的做法是给一个新的名字。事实上也是如此,我们没有重新定义strings.Split,几年前,标准库引入了strings.Fields函数。
Example: strings.Fields(x)
"hello world" => {"hello", "world"}
"hello world" => {"hello", "world"}
" hello world" => {"hello", "world"}
"hello world " => {"hello", "world"}
遵守兼容性原则可以大大简化软件工程。当程序员理解程序时,你无需把时间纳入考量范围内,2015 年使用的strings.Split和今年使用的strings.Split是一样的。工具也是如此,比如重构工具可以随意地将strings.Split在不同包内移动而不用担心函数含义随着时间发生改变。
实际上,Go 1 最重要的特性就是其语言不变性。这一特性在官方文档中得到明确,golang.org/doc/go1compat:
It is intended that programs written to the Go 1 specification will continue to compile and run correctly, unchanged, over the lifetime of that specification. Go programs that work today should continue to work even as future “point” releases of Go 1 arise (Go 1.1, Go 1.2, etc.).
所有 Go 1.x 版本的程序在后续版本仍能继续编译,并且正确运行,行为保持不变。今天写了一个 Go 程序,未来它仍能正常工作。Go 官方同样也对标准库中的函数作出了承诺。
兼容性和版本有啥管理?当今最火的版本管理方法——语义化版本是鼓励不兼容的,这意味着你可以通过语义化版本号,更轻易地作出不兼容的改变。
如何理解?
语义化版本有着vMAJOR.MINOR.PATCH的形式。如果两个版本有着系统的主版本号,那么后一个版本应该向前兼容前一个版本。如果主版本号不同,那他俩就是不兼容的。该方法鼓励包的作者,如果你想作出不兼容的行为,那改变主版本号吧!
对于 Go 程序来说,光改变主版本号还不够,两个主版本号如果名字一模一样,阅读代码还是会造成困扰。
看起来,情况变得更加糟糕。
假设包B期望使用 V1 版本的string.Split,而C期望使用 V2 版本的string.Split。如果B和C是分别构建的,那 OK。

但如果有一个包A同时导入了包B和C呢?那该如何选择string.Split的版本?

针对Go modules的设计思想,官方意识到兼容性是最基础的原则,是必须支持、鼓励和遵循的。Go 的 FAQ 中写到:
Packages intended for public use should try to maintain backwards compatibility as they evolve. The Go 1 compatibility guidelines are a good reference here: don’t remove exported names, encourage tagged composite literals, and so on. If different functionality is required, add a new name instead of changing an old one. If a complete break is required, create a new package with a new import path.
大致意思是如果新旧两个包导入路径相同,那它们就应该被当作是兼容的。
这和语义化版本有什么关系呢?兼容性原则要求不同主版本号之间不需要有兼容性上的联系,所以,很自然地要求我们使用不同的导入路径。而Go modules中的做法是把主版本号放入导入路径,我们称之为语义化导入版本(Semantic import versioning)。

在这个例子中,my/thing/v2表示使用版本 2。如果是版本 1,那就是my/thing,没有显式在路径指定版本号,所以路径成为了主版本号的一部分,以此类推,版本 3 的导入路径为my/thing/v3。
如果strings包是我们开发者自己的模块,我们不想增加新的函数Fields而是重新定义Split,那么可以创建两个模块strings(主版本号 1)和strings/v2(主版本号 2),这样可以同时存在两个不同的Split。

依据此路径规则,A、B和C都能构建成功,整个程序都能正常运行。开发者和各种工具都能明白它们是不同的包,就像crypto/rand和math/rand是不同的一样显而易见。
让我们回到那个不可构建的程序。把strings抽象成包D,,这时候若不使用语义化导入版本方法,这样就遇到了经典的“钻石依赖问题”:B和C单独都能构建,但放在一起就不行。如果尝试构建程序A,那该如何选择版本D呢?

语义化导入版本切断了“钻石依赖”。因为D的版本 2.0 有不一样的导入路径,D/v2。

原则 #2:可重复性
第二原则是程序构建必须具有可重复性,一个指定版本包的构建结果不应随时间改变。在该原则下,今天我编译代码的结果和其他程序员明年编译的结果是匹配的。大部分包管理系统并不保证一点。
在第一小节我们也看到了,基于GOPATH的go get用的不是最新就是最旧的D。你可能认为,“go get当然会犯错误:它对版本一无所知”。但其实其他一些包管理工具也会犯同样的错误,这里以Dep为例。(Cargo和Bundler也类似)
Dep要求每一个包包含一个manifest来存放元数据,记录下对所有依赖的要求。当Dep下载了C,它读入C的元数据,知道了C需要D 1.4之后的版本。然后Dep下载了最新版本的D来满足这一限制。
假设在昨天,D最新版本是 1.5:

而今天,D更新为了 1.6:

可以看出,该决策方法是不可重复的,会随时间发生改变。
当然,Dep的开发者意识到了这一点,它们引入了第二个元数据文件——lock 文件。如果C本身是一个完整的程序,当 Go 调用package main的时候,lock 文件会记录下C使用依赖的确切版本,而当需要重复构建时,lock 文件内所记录的依赖具有更高的优先级。也就是说,lock 文件同样能保证重复性原则。
但 lock 文件只是针对整体程序而言——package main。如果C被别的更大程序所使用,lock 文件就无效了,库C的构建仍会随着时间的改变而改变。
而Go modules的算法非常简单,那就是“最小版本选择算法”——每一个包指定其依赖的最低版本号。比如假设B 1.3要求最低D 1.3,C 1.8要求最低D 1.4。Go modules不会选择最新的版本,而是选择最小能满足要求的版本,这样,构建的结果是可重复的。
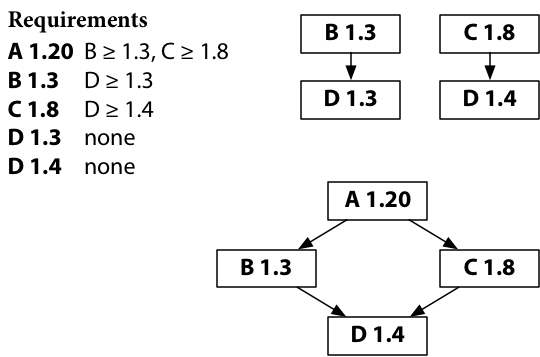
如果构建的不同部分有不同最低版本要求,go命令会使用最近的那个版本。如图所示,A构建时发现同时有D 1.3和D 1.4的依赖,由于 1.4 大于 1.3,所以构建时会选择D 1.4。D 1.5或者D 1.6存在与否并不会影响该决策。
在没有 lock 文件的情况下,该算法依然保证了程序和库的可重复性构建。
原则 #3:可合作性
第三原则是可合作性。为了维护 Go 包的生态,我们追求的是一个统一的连贯的系统。相反,我们想避免的是生态分裂,变成一组一组互相之间不可合作的包。
若开发者们不合作,无论我们使用的工具有多么精巧,技巧多么高超,整个 Go 开源生态一定会走向分裂。这里隐含的意思是,为了修复不兼容性,必须要合作,我们不应排斥合作。
还是拿库C 1.8举例子,它要求最低版本D 1.4。由于可重复性原则,C 1.8构建会使用D 1.4。如果C 1.8是被其他更大的程序所依赖,且该程序要求D 1.5,那根据最小版本选择算法,会选择D 1.5。这时候构建仍是正确的。
现在问题来了,D 的作者发布了 1.6 版本,但该版本有问题,C 1.8无法与该版本构建。

解决的方法是C和D的作者合作来发布 fix。解决方法多种多样。
C 可以推出 1.9 版本,规避掉D 1.6中的 bug。

D 也可以推出 1.7 版本,修复其存在的 bug。同时,根据兼容性原则,C 1.9可以指定其要求最低D 1.7。

再来复盘一下刚才的故事,最新版本的C和D突然不能一起工作了,这打破了 Go 包的生态,两库的作者必须合作来修复 bug。这种合作对生态是良性的。而正由于Go modules采用的包选择算法/可重复性,那些没有显式指定D 1.6的库都不会被影响。这给了C和D的作者充分的时间来给出最终解决方案。
结论
以上是 Go 版本管理的三原则,也是Go modules区别于Dep,Bundler和Cargo的根本原因。
- 兼容性,程序中所使用的名字不随时间改变。
- 可重复性,指定版本的包构建结果不随时间改变。
- 可合作性,为了维护 Go 包的生态,互相必须易于合作。
三原则来自于对年复一年软件工程的思考,它们互相巩固,是一个良性的循环:兼容性原则使用的版本选择算法带来了可重复性。而可重复性保证除非开发者显式指定,否则构建不会使用最新的、或是有问题的库,这给了我们时间来修复问题。而这种合作性又能保证兼容性。
Go 1.13中,Go modules已经可用于生成环境,很多公司,包括 Google 已经接纳了它。Go 1.14和Go 1.15会带来更多方便开发者的特性,它的最终目标是彻底移除GOPATH。
具体Go modules的使用方法,可以参考这个系列博客Using Go Modules。